This page presents the Relational Approach to Syntax which is a programme I've been developing for several years. I've listed the papers I've written but I've also taken the opportunity to explain each one briefly so that readers get a sense of how they fit together rather than reading them as isolated texts.
If you have questions or comments or ideas, don't hesitate to get in touch.
Mark de Vos
The Relational Approach to Syntax (Normalization grammar) is a minimalist model of syntax where basic Narrow Syntactic operations are driven by a process known as Normalization of relations (De Vos 2008). These are not merely postulates that were invented by me (Mark de Vos); rather, they are "real" insofar as they were independently theorized as universal constraints on how relations can be represented. Normalization can be seen as a set of constraints on information structure that can either drive syntactic derivations or constrain syntactic representations (depending on one's perspective). This means that Normal Forms can be construed as LF interface conditions which determine the nature of syntactic computation.
What the Relational Approach/Normalization Grammar does is ask the question: if we assume that these constraints exist, then (a) what kind of syntactic theory do they give rise to (what are the properties of the resulting system) and (b) does that system bear any resemblance to the syntactic systems exhibited in natural language? The answers to these questions are quite interesting. The resultant system is similar in many ways to Minimalism and I'd accordingly call it radically minimalist. Furthermore, it makes interesting predictions about natural language too.
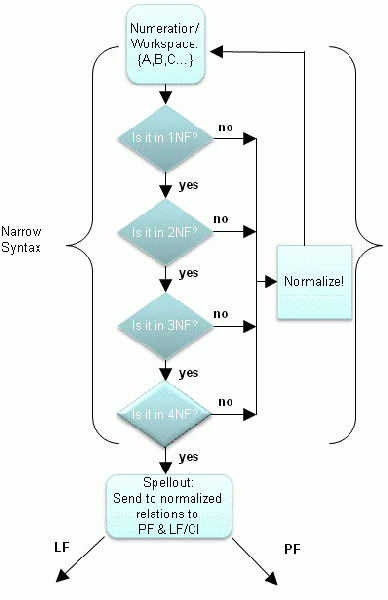
The standard Y/T-model of Minimalist syntax is illustrated below. One starts with a numeration; narrow syntax builds representations through Merge, Move and Agree. The resulting representation is sent to LF and PF for interpretation.
In a Relational/Normalization system, we ask a fundamental question: what is narrow syntax actually? What derives its basic operations of Merge, Move and Agree (in other words, we need to go beyond the argument of conceptual necessity). The tentative answer is that narrow syntax is simply a way of representing relations between features in well-formed ways. "Well-formed" must mean with respect to the interfaces.
But what do we mean by "well-formed" precisely? To answer this, the Relational/Normalization approach draws on Relational Theory for a mathematically precise set of answers to this question. Relations are constrained by constraints known as "Normal Forms". By implication, the role of syntax is to create representations that are well-formed with respect to these. This means that we can adjust the Y/T-model and give specific content to what we mean by "Narrow Syntax".
These lead to the following bare output conditions:
Implications for the narrow syntactic architecture
Implications for broader theory
Papers on the Relational approach to Syntax:
| The basic tenets of a normalization-driven syntax are explained in the following paper. If we adopt a restrictive but precise view of syntactic relations (Merge/Agree) as partial orders then we can ask a question: what kinds of structures can be represented and what might be the restrictions on these? I adopt the constraints imposed by the Relational Model (from Database theory) because these are well worked out, mathematically precise and apply universally to relational models. I then demonstrate how these constraints derive important Minimalist syntactic architecture (e.g. (binary) Merge, chain formation etc.) and simplify these (e.g. It is not necessary to have both Binary Merge and Set (n-ary) Merge). The result is a radically minimalist framework where the nature of the interface output conditions (made concrete in terms of Normal Forms) determine the nature of Narrow Syntax -- thus supporting the Strong Minimalist Hypothesis. |
Visualizing normalization: Here is a link to a PowerPoint presentation which provides a graphic explanation of the concepts explained in the Lingua (2008) paper.
Codd's original article can be found here:
| The normalization approach to syntax is developed in a paper on evolution of language. If we adopt the idea that the structures of natural language are constrained by universally applicable Normal Forms, then that also allows us to ask and answer questions about language evolution e.g. given the cognitive ability to normalize a relational structure to a certain level (e.g. NF2), what are the structures that such a being might be able to compute? This provides us a with a "pathway" for how language might have evolved and the model makes precise predictions about the types of constructions available to a being at each point along the way. The paper argues that the ability to store a large lexicon was a locus of evolutionary selection -- mechanisms of organizing that knowledge yield increased fitness. The paper then argues that the same mechanisms that allow organization of lexical knowledge can also be exapted for organization of syntactic knowledge. The ability to compute natural language syntax thus grows in parallel with the ability to organize a mental lexicon. |
|
In the following papers, I explore a different aspect of syntactic relations, namely how they might be linearized. This area is related but logically separate to the work on normalization (it is possible to pursue a linearization approach without adopting the idea that syntax is really all about Normalization of relations. The basic premise explored in all these papers is the idea that linearization of syntactic structure is a function of the syntactic relations present within that structure. Crucially, the morphology plays an important role in realizing the various options available to a language. |
How and movement occurs and how Morphology constrains how linearization occursThe following papers all represent my early work on linearization of syntactic relations. The paper on expletives shows how EPP effects can be derived from linearization considerations alone without having to stipulate that subjects must raise to SpecTP. As such, it resolves an important syntactic puzzle and simplifies the ontology of syntactic categories. The basic insight is that features in a single chain may be spelled out in different positions if the morphology of the language. In languages with "there"-type expletives, it is argued that "there" is an overt realization of pure phi features. The fact that it must be spelled out "high" is a function of the Agreement relationships which those features enter into. The paper on Afrikaans adpositions looks at doubling phenomena among Afrikaans adpositions (also visible in German and Dutch). Similarly to the EPP paper, the paper argues that doubling and postpositions occur when the morphology spells out two distinct points of a chain. It does so because of the need to linearize the syntactic relationships between the adposition and the DP.
|
Specifiers, heads and movement to Specifier positionsThe paper about the spec-head asymmetry explores the relationships between heads and specifiers. The SPIL paper is a development of an earlier paper in Groninger Arbeiten zur germanistischen Linguistic. The papers are similar in some ways but the later paper includes some additional insights. These papers attempt to show how English word order can be accomodated within the relational approach to linearization. In particular, it focusses on the relationships between specifiers and heads and shows (surprisingly) that the evidence that specifiers precede heads is not very clear in English. It is argued that it is possible (under certain circumstances) for a head to precede its specifier -- even if that would result in a "crossing tree" which is impermissible with traditional syntactic trees (within the approach adopted here, a syntactic tree need not have a "crossing" node -- but it's linearization can). The papers also attempt to explore how a locality condition on spelling out of relations might work. The poster about Hollmberg's Generaliztion/Object Shift is a development of this work on specifiers. I am able to demonstrate how the shifted and non-shifted constructions are merely equally optimal outputs of the linearization of the same underlying syntactic structure. In particular, there is no need for object movement in the underlying syntax i.e. object shift is a PF effect. |
The importance of Head MovementThe following paper examines head movement and its role in syntax. Head-movement has sometimes been considered to be a bit odd in the typology of movement types. This paper demonstrates a surprising but important conclusion: head movement makes computation of linearization easier. With the relational linearization approach, it is immediately apparent that (a) although the assumptions are reasonable and simple, (b) linearization is far from a simple process. In particular, a given syntactic structure could be linearized in a number of different ways -- but only a few of them are "optimal" (there is a clear similarity with Optimality Theory -- although within the Relational approach, the constraint set is trivial). What this paper shows is that head movement (bundling of features) serves to simplify the linearization options considerably. In other words, far from being an "imperfection", Head Movement plays an integral role in the linearization process. The paper also demonstrates how the head movement constraint can be derived from relational considerations: representations which respect the HMC are more easily linearized than those that do not. |
Last Modified: Tue, 22 Nov 2016 16:42:18 SAST